Appearance
创建有效的实证评估
在定义成功标准后,下一步是设计评估来衡量 LLM 对这些标准的表现。这是提示工程循环中的重要组成部分。
本指南重点介绍如何开发测试用例。
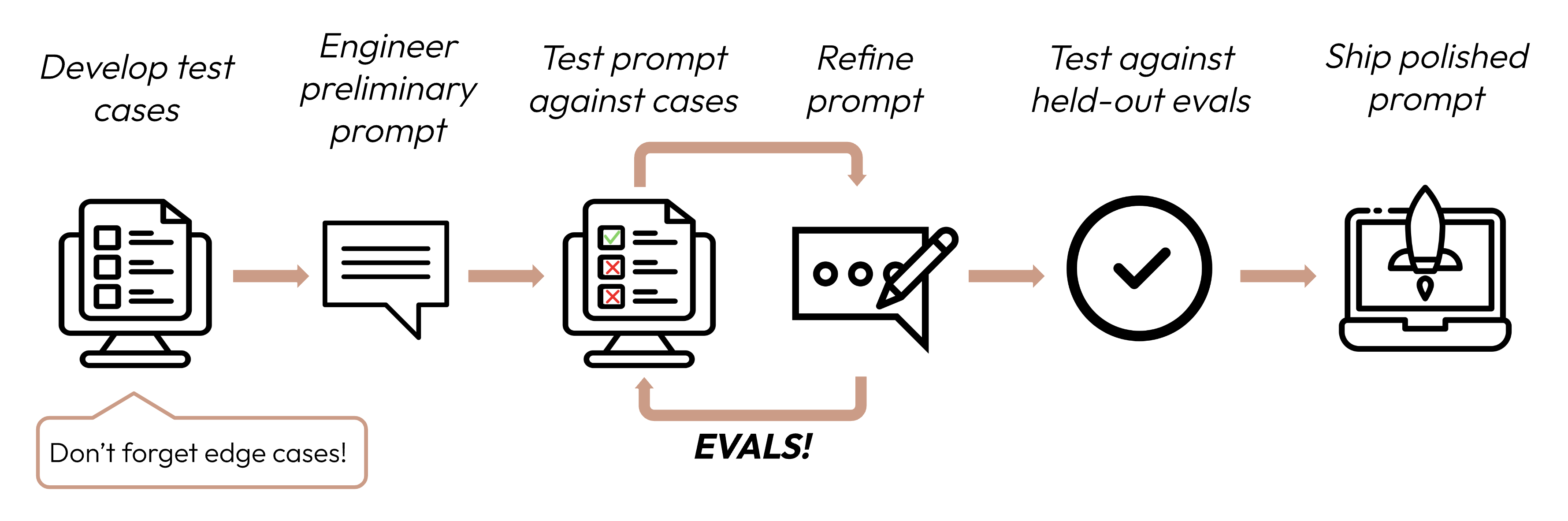
构建评估和测试用例
评估设计原则
- 针对具体任务:设计能反映真实世界任务分布的评估。别忘了考虑边缘情况!
- 尽可能自动化:构建问题时要便于自动评分(如多选题、字符串匹配、代码评分、LLM 评分)。
- 数量优先于质量:更多的自动评分问题(即使信号略低)比少量人工评分的高质量评估要好。
边缘情况示例
- 不相关或不存在的输入数据
- 过长的输入数据或用户输入
- [聊天用例] 糟糕的、有害的或不相关的用户输入
- 模糊的测试用例,即使人类也难以达成评估共识
评估示例
- 任务保真度(情感分析)- 精确匹配评估
- 评估内容:精确匹配评估用于衡量模型输出是否与预定义的正确答案完全匹配。这是一个简单、明确的指标,非常适合有明确分类答案的任务,如情感分析(积极、消极、中性)。
- 评估测试用例示例:1000 条带有人工标注情感的推文。
- 一致性(FAQ 机器人)- 余弦相似度评估
- 评估内容:余弦相似度通过计算两个向量(在本例中是使用 SBERT 的模型输出句子嵌入)之间角度的余弦值来衡量它们的相似度。值越接近 1 表示相似度越高。这非常适合评估一致性,因为相似的问题应该产生语义相似的答案,即使措辞不同。
- 评估测试用例示例:50 组问题,每组包含几个改写版本。
- 相关性和连贯性(摘要)- ROUGE-L 评估
- 评估内容:ROUGE-L(面向召回的摘要评估 - 最长公共子序列)用于评估生成摘要的质量。它测量候选摘要和参考摘要之间最长公共子序列的长度。高 ROUGE-L 分数表明生成的摘要以连贯的顺序捕捉了关键信息。
- 评估测试用例示例:200 篇带有参考摘要的文章。
- 语气和风格(客服)- 基于 LLM 的李克特量表
- 评估内容:基于 LLM 的李克特量表是一种使用 LLM 来判断主观态度或感知的心理测量量表。在这里,它用于对回复的语气进行 1-5 分的评分。它非常适合评估传统指标难以量化的细微方面,如同理心、专业性或耐心。
- 评估测试用例示例:100 个客户询问,带有目标语气(同理心、专业、简洁)。
- 隐私保护(医疗聊天机器人)- 基于 LLM 的二元分类
- 评估内容:二元分类用于判断输入是否属于两个类别之一。在这里,它用于判断回复是否包含 PHI(个人健康信息)。这种方法可以理解上下文,识别规则系统可能遗漏的微妙或隐含的 PHI。
- 评估测试用例示例:500 个模拟的患者询问,部分包含 PHI。
- 上下文利用(对话助手)- 基于 LLM 的序数量表
- 评估内容:类似于李克特量表,序数量表在固定的有序量表(1-5)上进行测量。它非常适合评估上下文利用,因为它可以捕捉模型引用和构建对话历史的程度,这对于连贯、个性化的互动至关重要。
- 评估测试用例示例:100 个多轮对话,包含依赖上下文的问题。
TIP
手动编写数百个测试用例可能很困难!让 Claude 帮你从基准测试用例集生成更多用例。
TIP
如果你不知道哪些评估方法可能有助于评估你的成功标准,也可以与 Claude 一起头脑风暴!
评分评估
在决定使用哪种方法对评估进行评分时,选择最快、最可靠、最可扩展的方法:
- 基于代码的评分:最快且最可靠,极易扩展,但对于需要较少规则刚性的复杂判断缺乏细微差别。
- 精确匹配:output == golden_answer
- 字符串匹配:key_phrase in output
- 人工评分:最灵活且质量最高,但速度慢且成本高。如果可能,应避免使用。
- 基于 LLM 的评分:快速且灵活,可扩展且适合复杂判断。先测试以确保可靠性,然后再扩展。
LLM 评分技巧
- 有详细、清晰的评分标准:“答案应该总是在第一句话中提到’Acme Inc.’。如果没有,答案自动评为’不正确’。”
- 一个特定用例,甚至该用例的特定成功标准,可能需要几个评分标准来进行全面评估。
- 实证或具体:例如,指示 LLM 只输出”正确”或”不正确”,或在 1-5 分范围内进行判断。纯定性评估难以快速和大规模评估。
- 鼓励推理:让 LLM 在决定评估分数之前先思考,然后丢弃推理过程。这可以提高评估性能,特别是对于需要复杂判断的任务。